




 Актуальная программа и навыки, которые нужны работодателям
Актуальная программа и навыки, которые нужны работодателям Python и его библиотеки, Jupyter Notebook, SQL, Git, AirFlow
Python и его библиотеки, Jupyter Notebook, SQL, Git, AirFlow Портфолио из 17+ проектов, каждый из которых проверит эксперт
Портфолио из 17+ проектов, каждый из которых проверит эксперт Полезные знакомства с экспертами по анализу данных и машинному обучению
Полезные знакомства с экспертами по анализу данных и машинному обучению Подготовка к собеседованиям и презентация прошлого опыта
Подготовка к собеседованиям и презентация прошлого опыта Сертификат о завершении курса
Сертификат о завершении курса
Специалисты по Data Science нужны везде, где хранят и обрабатывают большие объёмы данных
Ещё их называют дата-сайентистами — Data Scientist
От промышленности и IT до банков и коммерции
Например, Data Scientist может определить кредитоспособность клиентов банка, улучшить работу светофоров или обучить колонку с Алисой новым командам

Спрос растёт, а самих дата-сайентистов пока не так много на рынке труда
 Всё больше компаний открывают отделы Data Science, чтобы оптимизировать бизнес‑процессы и увеличивать прибыль
Всё больше компаний открывают отделы Data Science, чтобы оптимизировать бизнес‑процессы и увеличивать прибыль- Специалистов по Data Science не хватает, поэтому у них большие зарплаты и компании борются за них
- У вас будет много разных интересных задач, но придётся всё время осваивать новые технологии и развиваться
Особенности курса
Плавный вход в Data Science
Идём от простого к сложному: вы начнёте с SQL и Python, а потом углубитесь в машинное обучение. Занятость не больше 15 часов в неделю.
Практика на реальных данных
Собрали кейсы Яндекса и наших партнёров — будете делать проекты, которые максимально приближены к настоящим бизнес‑задачам.
Общение с экспертами
На воркшопах и вебинарах, во время лайвкодинга и QA‑сессий. Ещё опытные дата‑сайентисты дадут обратную связь по вашим проектам.
Подготовка к собеседованиям
Объясним, как пройти технический отбор и использовать предыдущий профессиональный опыт в новой сфере.
Есть базовый и расширенный форматы
Расширенный курс на 4 месяца длиннее, зато:
• Получите больше навыков, чтобы быстрее вырасти до уровня middle
• Добавите в портфолио ещё 5 проектов
• Получите реальный опыт в Мастерской Практикума
• Получите больше навыков, чтобы быстрее вырасти до уровня middle
• Добавите в портфолио ещё 5 проектов
• Получите реальный опыт в Мастерской Практикума

Освоите курс с нуля за 13 месяцев
Мощный набор навыков и инструментов
Это сейчас действительно актуально и требуется во всех вакансиях.
Python
Jupyter Notebook
Git
SQL
Командная строка
Pandas
NumPy
Matplotlib
Seaborn
SciPy
Scikit-learn
CatBoost
LightGBM/XGBoost
Shap
Optuna
AirFlow
MLFlow
Spark
Hugging Face
PyTorch
Научитесь применять нейросети так, чтобы они работали вместе с вами, а не вместо вас
ИИ будет усиливать ваши навыки, а вы — критически оценивать его решения
Ещё нейросети сделают ваше резюме заметнее: 73% работодателей поддерживают внедрение ИИ в рабочие процессы, а больше половины — обращают внимание на такие умения при найме
Регулярно обновляем программу, чтобы вы проходили только актуальное
Есть базовый и расширенный форматы — со вторым вы быстрее вырастете до уровня middle
7 тем・1 проект・~8 часов
Бесплатно
Основы Python и анализа данных
Узнаете основные концепции анализа данных и поймёте, чем занимается Data Scientist.
А после бесплатной части выберете подходящий формат курса: базовый или расширенный.
1
3 спринта・3 темы・7 недель
Основы анализа данных с помощью SQL
1 проект・2 недели
Проект по модулю о SQL
Закрепите навыки извлечения данных с помощью SQL. Очистите и подготовите их для анализа, а потом соберёте витрину данных для решения ad‑hoc‑задачи бизнеса. Оформите отчёт с результатами.
2
4 спринта・4 темы・8 недель
Анализ данных с помощью Python
1 проект・2 недели
Проект по модулю о Python
Научитесь очищать и предварительно обрабатывать данные. Проведёте исследовательский анализ и визуализируете результаты. Подготовите рекомендации для бизнеса и презентуете их.
3
3 спринта・3 темы・6 недель
Основы машинного обучения и линейные модели
1 проект・2 недели
Проект по линейным моделям
Пройдёте полный цикл создания ML-решения: от предобработки данных и EDA до обучения моделей для задач регрессии и классификации, подбора гиперпараметров и определения наилучшего решения с точки зрения метрик.
4
4 спринта・4 темы・8 недель
Модели на основе деревьев
1 проект・2 недели
Проект по модулю о моделях на основе деревьев
Будете строить решения на основе алгоритмов деревьев. Извлечёте данные с помощью SQL, проведёте их очистку и исследовательский анализ, подготовите признаки для обучения модели и поэкспериментируете с её параметрами, чтобы добиться заданного уровня качества. Освоите валидацию и интерпретацию результатов модели. Оформите решение и логику работы модели в виде технической документации.
5
3 спринта・3 темы・6 недель
Валидация и тестирование моделей
1 проект・2 недели
Проект по модулю о валидации и тестировании моделей
Пройдёте полный цикл работы с моделью машинного обучения в продакшн-среде: научитесь читать и дорабатывать готовый код, подготовите модель к инференсу и реализуете её запуск на новых данных с помощью Airflow. Закрепите навыки работы с пайплайнами, автоматизацией процессов и системой контроля версий Git.
2 недели
Подготовка к собеседованиям по Data Science
Узнаете, как проходит техническая часть собеседований. Разберёте примеры задач, которые предлагают соискателям. Потренируетесь отвечать на вопросы, которые часто задают нанимающие менеджеры. Всё это позволит чувствовать себя уверенно на реальном интервью.
1 проект・3 недели
Итоговый проект базового курса
Пройдёте через весь жизненный цикл проекта по Data Science: от анализа данных и проблематики бизнеса до презентации результатов и внедрения решения.
Дополнительно
Нейросети для специалиста по Data Science
Узнаете, как и зачем использовать нейросети в вашей профессии. Освоите техники работы с разными AI‑инструментами, сможете формулировать эффективные промпты и критически оценивать результаты.
+5 спринтов・+4 проекта・+15 недель
Расширенный курс «Специалист по Data Science»
У этого курса есть расширенный формат: стоит дороже, но включает в себя больше тем и проектов — чтобы усилить портфолио и повысить шансы на быстрое трудоустройство.
1 проект・3 недели
Итоговый проект расширенного курса
Тоже пройдёте весь жизненный цикл проекта по Data Science, но столкнётесь с новыми техническими задачами: обработкой больших данных на PySpark и управлением экспериментами через MLflow. У вас будет выбор из двух датасетов, на которых можно выполнять проект.
Карьерный центр・1 месяц
Карьерный трек: подготовка к трудоустройству
Составите резюме, которое привлечёт внимание рекрутеров, и напишете сопроводительное письмо для откликов на вакансии. Узнаете, как правильно оформлять портфолио, и построите стратегию поиска работы.
Обратите внимание: если курс оплачивает ваш работодатель, у вас не будет карьерного трека.
Обратите внимание: если курс оплачивает ваш работодатель, у вас не будет карьерного трека.
Карьерный центр・До 6 месяцев
Карьерный трек: акселерация
Акселерация — активный поиск работы с поддержкой HR‑экспертов. Будете откликаться на вакансии, делать тестовые и ходить на собеседования, а мы вас дистанционно поддержим. Например, расскажем, какие ошибки бывают в общении с работодателем и как их избежать. Акселерация может продолжаться до 6 месяцев — обычно этого достаточно, чтобы получить первую работу в IT.
Получите сертификат о завершении курса

Очень много практики
Соберёте солидное портфолио: в базовом курсе сделаете 17 проектов, а в расширенном — 22
Будете решать конкретные задачи бизнеса и разбирать кейсы из практики. Проекты проверят эксперты и подскажут, что у вас получается хорошо, а что нужно развивать.
Проекты от настоящих заказчиков и хакатоны, чтобы получить реальный опыт
В Мастерской Практикума сможете поучаствовать в реальных проектах, почувствовать себя частью команды разработки и наладить полезные связи

Участники курса разработали решение для поиска каверов в Яндекс Музыке. Они сравнивали тексты песен и искали похожие в огромной базе данных с помощью технологий, которые освоили на курсе: NLP, мультиязычные эмбеддинги, приближённый поиск ближайших соседей, Learning to Rank.

Участники курса поработали с Буше — крупной сетью булочных и кафе в Санкт‑Петербурге. На основе полученных данных они обучили ML‑модели предсказывать вероятности оттока клиентов.

Вместе с Samokat.tесh мы организовали воркшоп для участников курса Специалист по Data Science. Они поработали с реальными задачами по отбору товаров для маркетплейса и посоревновались на платформе Kaggle.

На хакатоне участники курса помогли Яндекс Маркету оптимизировать процесс выбора упаковки: разработали продукт, который определяет нужные упаковочные материалы по описанию товара.
Ещё 7 месяцев после курса бесплатно помогаем с поиском работы — для этого у нас целый карьерный центр
Готовим к выходу на рынок IT: объясняем, как использовать предыдущий опыт и презентовать новые навыки

Резюме и сопроводительные письма
Изучаем ваш опыт и объясняем, как выделяться среди других кандидатов
Пробные собеседования
Проводим и технические собеседования с нанимающими специалистами, и интервью с рекрутерами
Вакансии специально для джуниор‑специалистов
Предлагаем вакансии, которые отвечают навыкам новичков, — на платформе Карьера от Яндекс Практикума
10 000+ пользователей Практикума уже нашли новую работу
Это данные исследования ВШЭ — они основаны на опыте пользователей Яндекс Практикума на российском рынке труда

Как устроен курс
Никаких давно снятых видео и длинных лекций
Вы проходите теорию и закрепляете её на практике в интерактивном тренажёре. Можно проходить курс во сколько и где удобно, главное — укладываться в дедлайны по проектам.
По расписанию только воркшопы с наставниками, остальное — в своём темпе
Опытные дата-сайентисты разбирают сложные кейсы и отвечают на ваши вопросы на живых воркшопах. Если не успеваете, можно смотреть в записи.
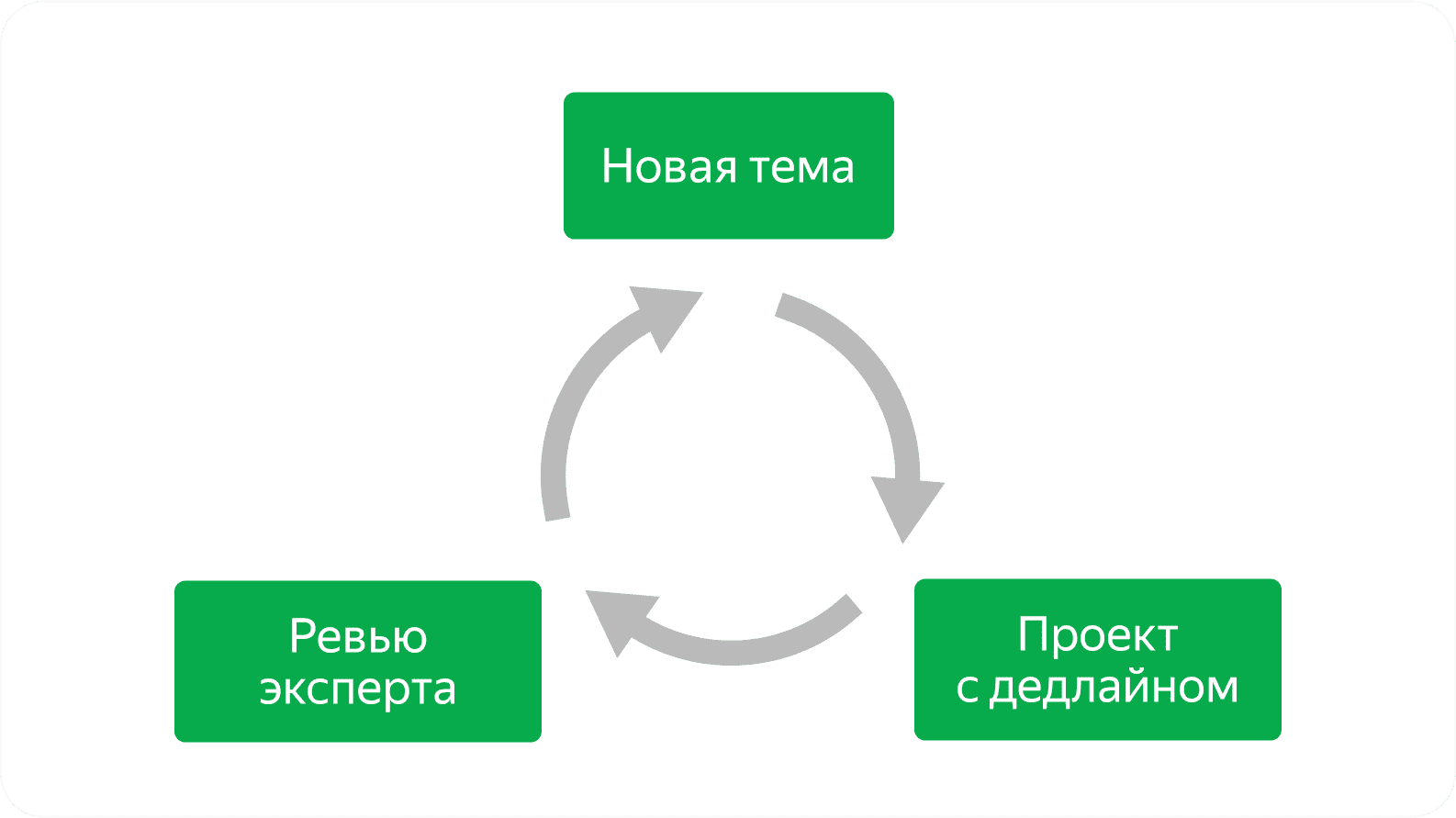
Курс в Практикуме похож на реальную работу
Программа поделена на спринты — отрезки по 2–3 недели, за которые вы изучаете тему и делаете проект. Потом отправляете его на ревью, а эксперты проверяют и комментируют. И тот же цикл дальше, пока не дойдёте до конца.
Будете заниматься сами, но не в одиночестве — вас поддержит заботливая команда Практикума
Эксперты помогают разобраться, если что-то непонятно
Это тоже практикующие специалисты по Data Science —обращайтесь к ним, когда возникнут вопросы по теории или проектам.

Сослан Табуев
Аналитик-разработчик в Яндексе.
В сфере Data Science работает 3 года, а в IT и математике — больше 20 лет.
В сфере Data Science работает 3 года, а в IT и математике — больше 20 лет.

Анна Осина
Руководитель отдела дата-анализа в AliExpress Россия.
Занимается Data Science больше 5 лет.
Занимается Data Science больше 5 лет.

Ольга Макаревич
Аналитик данных в Университете 2035.
Работает в сфере Data Science 2 года.
Работает в сфере Data Science 2 года.
Купить курс — дело серьёзное, поэтому помогаем сэкономить
Оплата курса целиком с выгодой до 20%
Когда решитесь на покупку, увидите итоговую стоимость — она зависит от способа оплаты: целиком или по частям.
Возврат денег
Если передумаете в первую неделю, нужно будет оплатить только время с начала вашей когорты. Если позже — время со старта когорты и расходы на организацию курса. Подробнее — в 7 пункте оферты.
Посмотреть оферту
Посмотреть оферту
Если у вас есть вопросы, оставьте заявку — мы позвоним
Менеджер расскажет о курсе и предложит персональную скидку
Отвечаем на вопросы
Подойдёт ли мне этот курс?
Можно ли освоить профессию Data Scientist с нуля за 13 месяцев?
Каким требованиям нужно соответствовать?
Кто будет помогать мне проходить курс?
Смогу ли я найти работу после курса?
А если я хочу работать в Яндексе?
Вы поможете мне найти работу?
Что делать, если я не справлюсь с нагрузкой?
Если не понравится, я могу вернуть деньги?
Получу ли я какой-то документ после курса?
Как можно оплатить?
На каком языке проходит курс?
Давайте поможем
Мы работаем с 09:00 до 18:00 по минскому времени и связываемся в течение одного дня. Если оставите заявку сейчас, то перезвоним уже в рабочее время.